The Making of a Scalable URL Shortener
This article was initially published as a thread of posts on X. For the sake of readability and long-term availability, it is now available here as a single-page article.
Post 1
A few months ago, I built a custom URL shortener. Quick refresher: a URL shortener does two things:
- Creates short URLs that map to long URLs
- Redirects short URL requests to those long URLs.
Designing this was a fantastic engineering challenge. Here’s a look at my design process!
A thread 🧵
Post 2
Let’s first start with the core requirements:
- Ultra-fast redirection
- Compact, very short URLs (a few characters)
- Batch URL creation
- TTL for short URLs (optional)
Post 3
There are plenty of cheap URL shortener services out there, but I chose to build in-house because:
- None of the existings met all our requirements
- Owning our URLs gives us more control (future-proofing & privacy)
- It allowed the team to see tech isn’t magic - It’s just well-applied engineering.
- It was an opportunity to experiment with a new tech stack (AWS lambdas, AWS DynamoDB & Go)
Post 4
For the slugs, I chose base62 (0-9A-Za-z) over base64 (A-Za-z0-9+/) because it is URL-friendly. I also considered base58 (removing 0, O, I and l to reduce visual confusion) as explained in Bitcoin source code, but the smaller slug space felt restrictive and not providing so much value. After all, short URLs aren’t meant for manual typing or reading.

Post 5
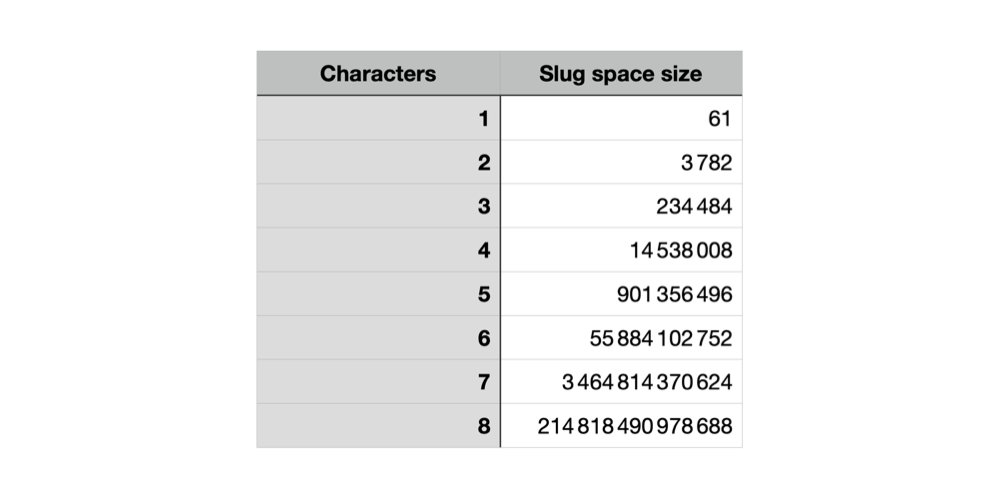
Starting with 4-characters slugs provided a large but manageable slug space: 62^4 = 14.776.336 unique slugs. To avoid slugs like “a” or “000a”, I enforced the 4-characters length by starting at “1000” and removing 62^3 = 238.328 entries. Switching to 5-character would expand our space by 901.356.496 additional slugs.
The trickiest part? Generating slugs in a consistent, atomic and non-deterministic way.
Post 6
Approach #1: Randomized Slugs ❌
The naive approach: generate a random 4-character slug, check the database for duplicates, and retry on collision. This doesn’t scale due to the risk of collisions as the slug space fills. It’s also challenging to make this atomic in a distributed system.
Post 7
Approach #2: Incremental Counter ❌
Another option was to increment a counter, converting each value to base62 for the slug. This avoids database reads and is straightforward, but it makes slug generation deterministic. An attacker could predict the next slug with base62(base10(latest_slug) + 1).
Post 8
Approach #3: Permutation of Slug Space ❌
We could keep a monotonically increasing counter and precompute a random-access permutation of the 62^4 possible slugs. An example for a slug space of size 5 could be [4, 3, 0, 1, 2]: first slug would be base62(4), then base62(3) and so on. While this avoids sequential patterns, it requires significant storage and doesn’t scale well — what happens when the slug space fills up?
Post 9
Approach #4: Format-Preserving Encryption (FPE) ✅
The final approach was to use format-preserving encryption (FPE), a bijective function creating a pseudorandom permutation using a secret key. This gives the appearance of randomness while remaining efficient. Plus, we can adapt it easily for 5 or 6-character slugs as needed.
Read more on FPE on Wikipedia: https://en.wikipedia.org/wiki/Format-preserving_encryption
Post 10
In DynamoDB, I store two main entities: a cursor (counter) starting at 62^3 = 238,328 (slugs start at ‘1000’) and the URL records (slug, created_at, expires_at, long_url). For batch creation of N URLs, the AWS Lambda reserves “the next N slugs” by atomically incrementing the cursor (thanks to DynamoDB’s atomic counters and strong consistency of UpdateItem with ReturnValue). This approach leaves room for other clients to reserve their own space if necessary.
The Lambda then generates and inserts short URLs into the database. Occasionally, slugs might be lost due to errors, but that’s acceptable. Ultimately, this process fills the slug space linearly 🙌.
Post 11
DynamoDB automatically handles short URL expiration with per-item TTLs. While TTL deletions occur eventually (up to a few days), I mitigated this by adding a filter expression on Query/Scan operations to ignore expired entries.
Post 12
With the system in place, redirecting a short URL involves parsing its slug, fetching the associated URL from DynamoDB, and redirecting the user either to the long URL (301) or a custom “not found” page (404).
Future improvements? Definitely! We could add warmed-up Lambdas, a back-office, support for manually generated slugs, and more. But for now, this custom URL shortener is live, scaling seamlessly, and running smoothly 🚀.
Thanks Sylvain & Raoul for proof-reading this 🤗